Protecting HANA against Ransomware Attacks – Data and Applications
A few weeks ago, I posted a blog entry about securing SAP HANA systems against ransomware attacks from a Systems and OS perspective. As noted in that webinar, this addresses some angles of attack of hackers, i.e. admins with privileged access and other avenues by which admin level authority might be commandeered. These are critical because only those accounts with write authority to HANA and other critical system files can encrypt them and hold the keys to these files until a ransom is paid. This is one of the most common exploits used by ransomware hackers. These types of attacks can be crippling and, without a strong recovery strategy, leave the attacked entity no choice other than to pay the hacker. Even with a good recovery strategy, it is possible to have multiple days without your key HANA and other systems which could be financially devastating.
But this only addresses some of the potential avenues of attack and a relatively small population of employees and/or contractors. The much larger population is composed of application users. Attacks focused on these individuals can result in all sorts of unpleasant outcomes, ranging from users being denied access to fraudulent orders being placed to money transfers occurring as if a “vendor” is being paid or a refund is being issued to a customer. But the ransomware hackers can be much more malicious, actually stealing data of value to the company, e.g. trade secrets, banking and credit card information, sales related data such as customer contact info, PII or other protected data. In these types of attacks, the stolen data is held in an undisclosed location and, if a ransom is not paid, the data is released publicly or sold to the highest bidder. These types of attacks may not be as devastating as the above mentioned encrypted files attack, but could result in embarrassing data releases, loss of competitive advantage, or even sanctions and fines from authorities.
In order to explore these types of attacks more and help customers to design strategies to combat them, I enlisted the help of Ryan Throop, Executive Security Consultant, IBM Security Services – SAP Security & GRC. IDG hosted a call sponsored by Bob Friske, IBM Brand Manager at TD Synnex (formerly Tech Data), on which we explored how customers can secure their SAP HANA systems against ransomware attacks with a applications and data. This webinar is available at https://www.cio.com/resources/225375/securing-your-sap-hana-systems-against-ransomware-attacks?brand_id=256&locale=1
Though we discussed protection of SAP HANA, some of the tools and techniques are appropriate for other systems of value including non-SAP ERP systems. The webinar is a little less than 30 minutes and has a special offer at the end for customers in North America.
Protecting SAP HANA systems against ransomware attacks – OS and Infrastructure
Cybersecurity threats seem to be everywhere. It seems only logical that systems with the largest financial impact would be perfect targets. This would imply that customers using SAP systems are being attacked and should be expending considerable effort to protect these critical systems. To that end, I did some internet research into how hackers target these systems and how to protect them. I realized that I was in over my head very quickly and enlisted the help of a few experts from IBM. After these conversations, I came to three conclusions.
- Ransomware is one of the most common forms of attack on SAP systems and certainly has the biggest financial impact.
- Hackers use a variety of methods to gain entry and hold data for ransom.
- Two avenues of protection must be pursued by every customer, one focused on the operating systems and infrastructure and the other focused on SAP data and applications.
I enlisted the help of Stephen Dominguez, WW Lead Consultant for AIX/Linux Security with IBM’s Systems Lab Services, and George Wilson, Security Architect / Security Team Lead with IBM’s Linux Technology Center. IDG hosted a call sponsored by Bob Friske, IBM Brand Manager at TD Synnex (formerly Tech Data), on which we explored how customers can secure their SAP HANA systems against ransomware attacks with a focus on operating systems and infrastructure. This webinar is available at https://www.cio.com/resources/form?placement_id=9e3b9689-abfd-4205-8e1e-e94070744ce0&brand_id=256&locale_id=1 . Though we discussed protection of SAP HANA, the tools and techniques are equally appropriate for other systems of value including non-SAP ERP systems.
The short 30 minute webinar has a special offer at the end for customers in North America. We will be posting another webinar in the near future focused on SAP data and applications.
IBM Power10 debuts with a new SAP Benchmark!
Today, SAP published a new SD 2-tier result for IBM’s soon to be announced Power E1080.[i] First the highlights:
- 174,000 SD Users
- 955,050 SAPS
- 120 cores
Wait, almost 1M SAPS with only 120 cores? HPE achieved 670,830 SAPS (122,300 users) with 224 cores on their Superdome Flex 280 with the Intel Xeon Platinum 8380H Processor in January, 2021.
This new result is almost 3 times the SAPS/core of HPE’s biggest and baddest system. (Funny note, autocorrect tried to change “baddest” to “saddest”). This new result is also about 33% faster, on a per core basis, than the previous Power 980 result published at the end of 2018. That is certainly not remarkable since Intel’s per core performance on this benchmark also increased about 69.5%, since 2017 … sorry, missed the decimal, 0.695%. (Comparing two Dell 2-socket results, Intel 8180 & Intel 8380).
Clearly, IBM has moved the microarchitecture technology ball forward with a huge improvement in per core performance. And that is significant in that Intel seems to have given up on the microarchitecture game and only seems to be focused on increasing the core count (now up to 40 per socket).
But isn’t the SD benchmark based on ECC 6.0 and primarily an app server benchmark, so do we really care if we are talking about SAP workloads? For that matter, isn’t HANA the name of the game now and how can we correlate this result against HANA workloads?
Yes and you can’t. I will answer the second question first. SAP rules forbid comparisons against different benchmarks and for good reason; they don’t have the same logic, application code, database usage, memory dependency or anything else for that matter. But, we will get to the impact on HANA a bit later in this blog.
The SD benchmark is rather removed from reality both by its age, its dependence on an outdated interface (the old and much loved SAP GUI, not) not to mention old non-HANA databases. Fun fact: since 2005, 96 results are used MaxDB or Sybase, 155 – IBM Db2, 52 – Oracle, 413 – Microsoft SQL and 0 used HANA. And since application servers can easily scale across dozens of systems, the performance per core doesn’t really matter all that much, and this equation usually boils down to $/SAPS.
At Hot Chips 2020, Bill Starke, IBM Power Chief Architect and Brian Thompto, Power10 core architect, revealed a bunch of amazing speeds and feeds including 2.25x the memory bandwidth for Power10 vs Power9 per socket.[ii] We know that HANA eats memory bandwidth for breakfast, lunch, dinner and all snacks in between. This new SD benchmark (and others that IBM will undoubtedly publish very soon) suggest that these new Power processors will be able to handle all workloads, including SAP HANA, with either fewer cores or with the same number of cores and tons of CPU cycles to spare.
It might be tempting to consider using a smaller Power10 system, but this is where the problem gets a bit sticky. HANA not only loves memory bandwidth, but unless you are going to provision a server with less memory than SAP recommends or use one of their tiered approaches, you still need the same quantity of memory regardless of server or microarchitecture. You could certainly reduce the number of cores per socket or go to slower chip speeds and this might be a very good approach for reducing HANA system costs for a lot of customers. Another option to consider is using those spare cycles for something else, after all HANA is supported by SAP for use with IBM PowerVM shared processor pools.
What other workloads might you use those cycles for? We could get into a big discussion about all sort of other workloads, like AI, HPC, etc., but how about we keep this simple? How about for the thing that the SD benchmark actually does test, application serving? Even with S/4HANA and Fiori, you still need application servers. And if you already purchased a server for HANA based on memory requirements and you have a ton of cycles left over, this means that the $/SAPS for those application servers essentially goes toward $0! I have not priced an Intel server lately, but I am pretty certain that the price is not even remotely close to $0.
For existing SAP on Power customers (both HANA and non-HANA), Power10 is going to be amazing, resulting in either better performance, lower cost or both! For customers still trying to decide on which type of system to use, I would strongly encourage a full landscape cost comparison be performed including production HANA and application servers, HA, non-prod and DR.
And as good a news as this is for on-premise customers, cloud vendors that offer HANA on Power, such as IBM, Syntax and SAP, should be even more excited about how they can decrease their costs while offering better solutions to their customers with Power10.
[i] https://www.sap.com/dmc/exp/2018-benchmark-directory/#/sd
[ii] https://www.nextplatform.com/2020/08/18/ibm-brings-an-architecture-gun-to-a-chip-knife-fight/
POWER10 – Memory Sharing and how HANA customers will benefit
As an in-memory database, SAP HANA is obviously limited by access to memory. Having massive CPU throughput with a small amount of memory could be useful for a an HPC application that needs to crunch through trillions of operations on a small amount of data. By comparison, a HANA system typically scales up with both CPU and memory at the same time.
Intel attempted to solve this problem through the use of large scale persistent DIMMs. Unfortunately, they delivered a completely unbalanced solution with their Cascade Lake processors that included a small incremental performance increase coupled with Optane DIMMs which are 3 to 5 times slower than DDR4 DIMMs (at best). By the way, the new “Barlow Pass” Optane DIMMs, that will be available with next gen Copper Lake and Ice Lake systems, will reportedly only deliver 15% bandwidth improvement over today’s “Apache Pass” DIMMs.[i] Allow me to clap with one hand at that yawner of an improvement. Their solution is somewhat analogous to a transportation problem where a road has 2 lanes and is out of capacity. You can increase the horsepower of each vehicle a bit and pack in far more seats in each vehicle, but it will likely to take longer to get all of the various passengers in different vehicles to their destination and they will most assuredly be much more uncomfortable.
IBM with POWER10, but comparison, attacked this problem by addressing all aspects simultaneously. As mentioned in part 1, POWER10 sockets have the potential of delivering 3 times the workload of POWER9 sockets. So, not a small incremental improvement as with Cascade Lake, but a massive one. Then they increased the bandwidth to memory by at least 4x, meaning they can keep the CPUs fed with data … and in case memory can’t keep up, they added support for DDR5 and its much faster speeds and throughput. Then they increased socket to socket communications bandwidth by a factor of four since transactional and analytic workloads, like HANA, tend to be spread across sockets and often need to access data from another socket. And just in case the system runs out of DIMM sockets, they introduced a new capability, “memory clustering” or “memory inception”[ii] which allows memory on another physical system to be accessed remotely (more on this later) with a 50 to 100ns latency hit[iii]. And just to make sure that I/O did not become the next bottleneck, they have doubled down on their previous leadership with being the first major vendor to support PCIe Gen4 by including support for PCIe Gen5 with a potential for twice the I/O throughput.
Using the previous analogy, IBM attacked the problem by tripling the horsepower of each vehicle with lots of extra doors and comfortable seats, quadrupling the number of lanes on the road and enabled each vehicle to support tandem additions. In other words, everybody can get to their destinations much faster and in great comfort.
So, what is this memory clustering? Put simply, it is an IBM developed technology which enables a VM on one system to map memory allocated to it by PowerVM on another system as if it was locally attached. In this way, a VM which requires more memory than is available on the system upon which it is running can be provided with that memory from one or more systems in the cluster. It does this through the same PowerAXON (IBM’s SMP interconnect technology) as is used within each system across sockets. As a result, the projected additional latency is likely to be only slightly higher than accessing memory across the NUMA fabric.
IBM described multiple different potential topologies, ranging from “Enterprise Class” at extreme bandwidth, to hub and spoke; mixing and matching CPU heavy with Memory heavy nodes to even multi-hop pod-level clustering of potentially thousands of nodes. With POWER10 featuring a 2 Petabyte memory addressability, the possibilities are mind boggling.
For HANA workloads, I see a range of possibilities. The idea that a customer could extend memory across systems is the utopia of “never having to say I’m sorry”. By that, I mean that in the bad old days (current times that is), if you purchased, for example, a 2TB system with all DIMM slots used, and your HANA instance needed a tiny amount more memory than available on the system, you had three choices: 1) let HANA deal with insufficient memory and start moving columns in and out of memory with all of the associated performance impact implied, 2) move the workload to a larger system at a substantial cost and a loss of the existing investment (which always brings a smile and hug from the CFO) or 3) if possible, shut down the instance and the system, rip out all existing DIMMs and replace them with larger ones (even more disruptive and still very expensive).
With memory clustering, you could harvest unused capacity in your cluster at no incremental cost. Or, if all memory was in use, you could resize a less important workload, e.g. a HANA sandbox VM or non-prod app server, and reallocate it to the production VM requiring more memory. Or you could move a less important workload to a different server potentially in a different data center or perhaps a much smaller system and reuse the memory using clustering. Or you could purchase a small, low GHz, small number of activated cores system to add to the cluster with plenty of available memory to be used by the various VMs in the cluster. The possibilities are endless, but you will notice, having to say to management that “I blew it” was not one of the options.
Does this take the place of “Storage Class Memory” (SCM) aka persistent memory? Not at all. In fact, POWER10 has explicit support for SCM DIMMs. The question is more of whether SCM technology is ready for HANA. At 3 to 5 times worse latency than DRAM, Intel’s SCM, Optane, most certainly is not. In fact, I call it highly irresponsible to promote a technology with barely a mention of the likely performance drawbacks as has been done by Intel and their merry band of misinformation brethren, e.g. HPE, Cisco, Dell, etc.
I prefer IBM’s more measured approach of supporting technology options, encouraging openness and ecosystem innovation, and focusing on delivering real value with solutions that make sense now as opposed to others’ approaches that can lead customers down a path where they will inevitably have to apologize later when things don’t work as promised. I am also looking forward to 2021 to see what sort of POWER10 systems and related infrastructure options IBM will announce.
[i] https://www.tomshardware.com/news/intel-barlow-pass-dimm-3200mts-support-15w-tdp
[ii] https://www.crn.com/news/components-peripherals/ibm-power10-cpu-s-memory-inception-is-industry-s-holy-grail-
https://www.servethehome.com/ibm-power10-searching-for-the-holy-grail-of-compute/hot-chips-32-ibm-power10-memory-clustering-enterprise-scale-memory-sharing/
[iii] https://www.hpcwire.com/2020/08/17/ibm-debuts-power10-touts-new-memory-scheme-security-and-inferencing/
POWER10 – Opening the door for new features and radical TCO reduction to SAP HANA customers
As predicted, IBM continued its cycle of introducing a new POWER chip every four years (after a set of incremental or “plus” enhancements usually after 2 years).[i] POWER10, revealed today at HotChips, has already been described in copious detail by the major chip and technology publications.[ii] I really want to talk about how I believe this new chip may affect SAP HANA workloads, but please bear with me over a paragraph or so to totally geek out over the technology.
POWER10, manufactured by Samsung using 7nm lithography, will feature up to 15 cores/chip, up from the current POWER9 maximum of 12 cores (although most systems have been shipping with chips with 11 cores or fewer enabled). IBM found, as did Intel, that manufacturing increasingly smaller lithography with maximum GHz and maximum core count chips was extremely difficult. This resulted in an expensive process with inevitable microscopic defects in a core or two, so they have intentionally designed a 16-core chip that will never ship with 15 cores enabled. This means that they can handle a reasonable number of manufacturing defects without a substantial impact to chip quality, simply be turning off which ever core does not pass their very stringent quality tests. This will take the maximum the number of cores in all systems up proportionately based on the number of sockets in each system. If that was the only improvement, it would be nice, but not earth shattering as every other chip vendor also usually introduces more or faster cores with each iteration.
Of course, POWER10 will have much more than that. Relative to POWER9, each core will feature 1.5 times the amount of L1 cache, 4x the L2 cache, 4x the TLB and 2x general and 4x matrix SIMD. (Sorry, not going to explain each as I am already getting a lot more geeky than my audience typically prefers.). Each chip will feature over 4 times the memory bandwidth and 4x the interconnect bandwidth. Of course, if IBM only focused on CPU performance and interconnect and memory bandwidths, then the bottleneck would naturally just be pushed to the next logical points, i.e. memory and I/O. So, per a long-standing philosophy at IBM, they didn’t ignore these areas and instead built in support for both existing PCIe Gen 4 and emerging PCIe Gen 5 and both existing DDR4 and emerging DDR5 memory DIMMS, not to mention native support for future GDDR DIMMs. And if this was not enough, POWER10 includes all sorts of core microarchitecture improvements which I will most definitely not get into here as most of my friends in the SAP world are probably already shaking their heads trying to understand the implications of the above improvements.
You might think with all of these enhancements, this chip would run so hot that you could heat an Olympic swimming pool with just one system, but due to a variety of process improvements, this chip actually runs at 3x the power efficiency of POWER9.
Current in-memory workloads, like SAP HANA, rarely face a performance issue due to computational performance. It is reasonable to ask the question whether this is because these workloads are designed with an understanding of the current limitations of systems and avoid doing more computationally intense actions to avoid delivering unsatisfying performance to users who are increasingly impatient with any delays. HANA has kind of set the standard for rapid response so delivering anything else would be seen as a failure. Is HANA holding back on new, but very costly (in computational terms) features that could be unleashed once a sufficiently fast CPU becomes available? If so, then POWER10 could be the catalyst for unleashing some incredible new HANA capabilities, if SAP takes advantage of this opportunity.
A related issue is that perhaps existing cores can deliver better performance, but memory has not been able to keep pace. Remember, 128GB DRAM DIMMS are still the accepted maximum size by SAP for HANA even though 256GB DIMMS have been on the market for some time now. As SAP has long used internal benchmarks to determine ratios of memory to CPU, could POWER10 enable to the use of much more dense memory to drive down the number of sockets required to support HANA workloads thereby decreasing TCO or enabling more server consolidation? Remember, Power Systems all featured imbedded, hardware/hypervisor based virtualization, so adding workloads to a system is just a matter of harnessing any unused extra capacity.
IBM has not released any performance projections for HANA running on POWER10 but has provided some unrelated number crunching and AI projections. Based on those plus the raw and incredibly impressive improvements in both the microarchitecture and number of cores, dramatic cache and TLB increases and gigantic memory and interconnect bandwidth expansions, I predict that each socket will support 2 to 3 times the size of HANA workloads that are possible today (assuming sufficient memory is installed).
In the short term, I expect that customers will be able to utilize TDI 5 relaxed sizing rules to use much larger DIMMs and amounts of memory per POWER10 system to accomplish two goals. For customers with relatively small HANA systems, they will be able to cut in half the number of sockets required compared to existing HANA systems. For customers that currently have large numbers of systems, they will be able to consolidate those into many fewer POWER10 sytems. Either way, customers will see dramatic reductions in TCO using POWER10.
As to those customers that often run out of memory before they run out of CPU, stay tuned for part 2 of this blog post as we discuss perhaps the most exciting new innovation with POWER10, Memory Clustering.
[i] https://twitter.com/IBMPowerSystems/status/1295382644402917376
https://www.linkedin.com/posts/ibm-systems_power10-activity-6701148328098369536-jU9l
https://twitter.com/IBMNews/status/1295361283307581442
[ii] Forbes – https://www.forbes.com/sites/moorinsights/2020/08/17/ibm-discloses-new-power10-processer-at-hot-chips-conference/#12e7a5814b31
VentureBeat – https://venturebeat.com/2020/08/16/ibm-unveils-power10-processor-for-big-data-analytics-and-ai-workloads/
Reuters – https://www.reuters.com/article/us-ibm-samsung-elec/ibm-rolls-out-newest-processor-chip-taps-samsung-for-manufacturing-idUSKCN25D09L
IT Jungle – https://www.itjungle.com/2020/08/17/power-to-the-tenth-power/
SAP Extends support for Business Suite 7 to 2027 and beyond … but the devil is always in the detail
The SAP world has been all abuzz since SAP’s announcement on February 4, 2020 about their extension of support for Business Suite 7 (BS7) which many people know as ECC 6.0 and/or related components. According to the press release[i], customers with existing maintenance contracts will be able to continue using and getting support for BS7 through the end of 2027 and will be able to purchase extended maintenance support through the end of 2030 for an additional 2 points over their current contracts.
It is clear that SAP blinked first although, in an interview[ii], SAP positions this as a “proactive step”, not as a reaction to customer pushback. Many tweets and articles have already come out talking about how customers now have breathing room and have clarity on support for BS7. And if I just jumped on the bandwagon here, those of you who have been reading my blog for years would be sorely disappointed.
And now for the rest of the story
Most of you are aware that BS7 is the application suite which can use one of several 3rd party database options. Historically, the most popular database platform for medium to large customers was Oracle DB, followed by IBM Db2. BS7 can also run on HANA and in that context is considered Suite on HANA (SoH).
What was not mentioned in this latest announcement is the support for the underlying databases. For this, one must access the respective SAP Notes for Oracle[iii] and Db2[iv].
This may come as a surprise to some, but if you are running Oracle 12.2.0.1, you only have until November of this year to move to Oracle 19c (or Oracle 18c, but that would seem pretty pointless as its support ends in June of 2021.) But it gets much more fun as that is only supported under normal maintenance until March, 2023 and under extended support until March, 2026. In theory, there might be another version or dot release supported beyond this time, but that is not detailed in any SAP Note. In the best-case scenario, Oracle 12 customers will have to upgrade to 19c and then later to an, as yet unannounced, later version which may be more transition than many customers are willing to accept.
Likewise, for Db2 customers, 10.5, 11.1 and 11.5 are all supported through December, 2025. The good news is that no upgrades are required through the end of 2025.
For both, however, what happens if later versions of either DB are not announced as being supported by SAP. Presumably, this means that a heterogeneous migration to Suite on HANA would be required. In other words, unless SAP provides clarity on the DB support picture, customers using either Oracle DB or IBM Db2 may be faced with an expensive, time consuming and disruptive upgrade to SoH near the end of 2025. Most customers have expressed that they are unwilling to do back to back migrations, so if they are required to migrate to SoH in 2025 and then migrate to S/4HANA in 2027, that is simply too close for comfort.
Lacking any further clarification from SAP, it still seems as if it would be best to complete your conversion to S/4HANA by the end of 2025. Alternately, you may want to ask SAP for a commitment to support your current and/or planned DB for BS7 through the end of 2027, see how they respond and how much they will charge.
[i] https://news.sap.com/2020/02/sap-s4hana-maintenance-2040-clarity-choice-sap-business-suite-7/
[ii] https://news.sap.com/2020/02/interview-extending-maintenance-for-sap-s4hana/
[iii] https://launchpad.support.sap.com/#/notes/1174136
[iv] https://launchpad.support.sap.com/#/notes/1168456
Does Intel’s Optane DC Persistent Memory decrease TCO for SAP?
When this new type of persistent memory DIMM (PMEM) was announced by Intel about a year ago, improving restart times was the most important factor cited by Intel and vendors of systems that utilize Intel Cascade Lake processors. Some of my previous blog posts have discussed the performance issues of PMEM and despite numerous searches, I can find no data presented by Intel or any other vendor to suggest that any improvement has occurred since this technology was made generally available. Over time, and perhaps as more customers realized that faster restarts at the cost of slower operational performance might not be very compelling, the message started to morph into saving money.
Regarding TCO specifically for SAP Suite on HANA (SoH) and S/4HANA, let’s start with the basic assertion, i.e. PMEM is less expensive than DRAM. This is documented by pricing which shows a 128GB PMEM DIMM costs approximately 60% of the cost of a 128 DRAM DIMM[i] on one site and 40%[ii] on another site. This discrepancy may result when one vendor shows effective prices and another list prices with the list price example showing a higher cost savings with PMEM.
I was interested to see what would happen with actual SAP instances. For comparison, let us start with a conventional DRAM memory system and assume that after using appropriate sizing tools, we have determined that an SoH or S/4HANA system requires a total of 6TB of memory to support 3TB of data with 3TB dedicated to system and HANA working memory. I chose 6TB because this fits perfects on most Intel systems using 4 processors and 48@128GB memory DIMMs. This config also has the added bonus of no waste at all and maximized performance since parallelism is optimized when every memory channel is used.
By comparison, we need to figure out how much memory is required if we utilize PMEM. The SAP note on persistent memory[iii] describes ratios of DRAM to PMEM ranging from 2:1 to 1:4. For SoH and S/4HANA, the advice given is to run QuickSizer, /SDF/HDB_SIZING or ZNEWHDB_SIZE depending on where you are starting from. I asked 3 different customers, one small, one medium and one very large, to provide me with the output of their sizing reports based on existing ECC systems. I have included two key sections for the midsized customer:
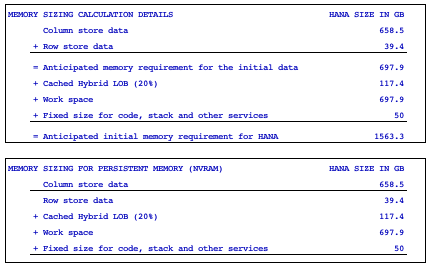
The Persistent Memory FAQ[iv] says: “Persistent memory can be used for the main storage of column store table that is typically the dominating factor of data space consumption in SAP HANA environments. Other areas like delta storage, caches, intermediate result sets or row store remain solely in dynamic RAM (DRAM). Disk LOBs (SAP Note 2220627) are also not part of the persistent memory.” If you add up the numbers above using this rule, you may notice that this means that when using persistent memory, the amount of data housed in PMEM vs. DRAM does not fit with any of the ratios mentioned earlier. Looking at the sizing reports that I obtained, the amount of PMEM vs. DRAM was more in the range of 1:1.5[v].
Now, let’s apply the very best ratio of the three reports, i.e. the very large customer, to our 6TB example above and we see that we need 6TB x .433 = 2.53TB PMEM and 6TB x .567 = 3.47TB DRAM. Assuming 128GB DIMMs, this translates to 20.2 PMEM DIMMs and 27.8 DRAM DIMMs which rounded up comes to 21 and 28 DIMMs, i.e. 49 DIMMs total. Clearly, this is one more than the max number (48) in a 4-socket system. In addition, SAP note 2786237 states that a configuration must have: “Homogeneous symmetrical assembly of DRAM and PMEM DIMMs with maximum utilization of all memory channels per processor”, so the minimum configuration would be 28 of each type of DIMM for a total of 56 DIMM slots.
To the best of my knowledge, no Cascade Lake system supports this number of DIMM slots. Several vendors support 64 DIMM slots on a 6 or 8-socket system. Those that do not would require a 96 DIMM slots configuration. At 64 DIMM slots, this configuration would waste the difference between the HANA memory requirement and the system configuration requirement, i.e. 540GB of DRAM and 1,508GB of PMEM would be wasted. At 96 DIMM slots, the waste would be 2,588GB and 3,556GB respectively. With either a 64 DIMM slot or 96 DIMM slot configuration, instead of a relatively affordable 4-socket system, a significantly more expensive 6 or 8-socket system would be required.
I chose to use the best pricing that I could find for DIMM prices assuming that other vendors would be able to match these prices. I then applied that pricing to those vendors that can utilize 64 DIMM slots on a 6 or 8-socket configuration. After a simple calculation[vi], the cost of just the memory of the DRAM+PMEM system came out $7,648 higher than the DRAM only system. And remember, this is before adding in any additional costs for more processors and a system which can support more processors.
Of course, 256GB DRAM DIMMs could be used, reducing the DRAM DIMM count to 15, but this raises a thorny issue; No appliance has been certified by SAP[vii] with 256GB DRAM DIMMs. Even if we ignored that issue and went out on a limb using TDI V5 relaxed rules, the significantly higher cost of 256GB DRAM DIMMs over 128GB DRAM DIMMs[viii] plus the need to round up to 24 DIMM slots would result in a configuration that was still substantially higher cost than the DRAM only configuration.
Any way that you cut it, the use of PMEM in a realistic SoH or S/4HANA configuration results in a higher cost of acquisition than a DRAM only configuration. In other words, as shown in the previous blog posts, performance takes a major hit when using PMEM for HANA, it does not save any money and actually costs more and the only potential gain comes from faster restarts.
[i] https://www.dell.com/en-us/work/shop/cty/pdp/spd/poweredge-r940/pe_r940_12229_vi_vp?configurationid=0163c707-0003-46a0-808a-3b55c864ba70
[ii] https://dcsc.lenovo.com/#/configuration/cto/7X13CTO1WW?hardwareType=server
[iii] https://launchpad.support.sap.com/#/notes/2786237
[iv] https://launchpad.support.sap.com/#/notes/2700084
[v] actual range was 41.5% to 43.3% for PMEM versus 58.5% to 56.7% for DRAM based on the small to very large reports
[vi] 48 x $2,670 = 128,160 (DRAM only), 32 x $1,574 + 32 x $2,670 = $135,808 (DRAM + PMEM)
[vii] https://www.sap.com/dmc/exp/2014-09-02-hana-hardware/enEN/appliances.html#viewcount=100
[viii] https://dcsc.lenovo.com/#/configuration/cto/7X13CTO1WW?hardwareType=server
Optane DC Persistent Memory – Proven, industrial strength or full of hype – Detail, part 3
In this final of a three part series, we will explore the two other major “benefits” of Optane DIMMs: fast restart and TCO.
Fast restart
HANA, as an in-memory database, must be loaded into memory to perform well. Intel, for years and, apparently up to current times, has suffered with a major bottleneck in its I/O subsystem. As a result, loading a single terabyte of data into memory could take 10 to 20 minutes in a best-case scenario. Anecdotally, some customers have remarked that placing superfast, all flash subsystems, such as IBM’s FlashSystem 9100, behind an Intel HANA system resulted in little improvement in load times compared to mid-range SSD subsystems. For customers attempting to bring up a 10TB storage/20TB memory HANA system, this could result in load times measured in hours. As a result, a faster way of getting a HANA system up and running was sorely needed.
This did not appear to be a problem for customers using IBM’s Power Systems. Not only has Power delivered roughly twice the I/O bandwidth of Intel systems for years, but with POWER9, IBM introduced PCIe Gen4, further extending their leadership in this area. The bottleneck is actually in the storage subsystem and number of paths that it can drive, not in the processor. To prove this, IBM ran a test with 10 NVMe cards in PCIe slots and was able to drive load speeds into HANA of almost 1TB/min.[I]. In other words, to improve restart times, Power Systems customers need only move to faster subsystems and/or add more or faster paths.
This suggests that Intel’s motivation for NVDIMMs may be to solve a problem of their own making. But this also raises a question of their understanding of HANA. If a customer is running a transactional workload such as Suite on HANA, S/4 or C/4, and is using HANA System Replication, wouldn’t at least one of the pair of nodes be available at all times? SAP supports near zero upgrades[ii], so systems, firmware, OS or even HANA itself may be updated on one of the pair of nodes while the other continues to operate, followed by a synchronization of changed data and a controlled failover so that the first node might be updated. In this way, cold restarts of HANA, where a fast restart option might make a big difference, may be driven down into a very rare occurrence. In other words, wouldn’t this be a better option than causing poor performance to everything due to radically slower DIMMs compared to DRAM as has been discussed in gory detail on the previous two posts of this series?
HANA also offers a quick restart option whereby HANA can be started and the database made available within minutes even though all of the columns have not yet been loaded into memory. Yes, performance will be pretty bad until all columns are loaded into memory, but for non-production systems and non-mission critical systems, this might be an acceptable option. Lastly, with HANA 2.0 SPS04, SAP now supports fast restart with conventional memory.[iii] This only works when the OS stays up and running, i.e. can’t be used when the system, firmware or OS is being updated, but this can be used for the vast majority of required restarts, e.g. HANA upgrades, patches and restarts when a bounce of the HANA environment is needed. Though this is not mentioned in the help documentation, it may even be possible to patch the Linux kernel while using the fast restart option if SUSE SLES is used with their “Live Patching” function.[iv]
TCO
Optane DIMMs are less expensive than DRAM DIMMs. List prices appears to be about 40% cheaper when comparing same size DIMMs. Effective prices, however, may have a much smaller delta since there exists competition for DRAM meaning discounts may be much deeper than for the NVDIMMs from Intel, currently the only source. This assumes full utilization of those NVDIMMs which may prove to be a drastically bad assumption. Sizing guidance from SAP[v]shows that the ratio of DRAM vs. PMEM (their term for NVDIMMs) capacity can be anything from 2:1 to 1:4, but it provides no guidance as to where a given workload might fall or what sort of performance impact might result. This means that a customer might purchase NVDIMMs with a capacity ratio of 1:2, e.g. 1TB DRAM:2TB PMEM, but might end up only being able to utilize only 512GB or 1TB PMEM due to negative performance results. In that case, the cost of effective NVDIMMs would have instantly doubled or quadrupled and would, effectively, be more expensive than DRAM DIMMs.
But let us assume the best rather than the worst. Even if only a 2:1 ratio works relatively well, the cost of the NVDIMMs, if sized for that ratio, would be somewhat lower than the equivalent cost of DRAM DIMMs. The problem is that memory, while a significant portion of the cost of systems, is but one element in the overall TCO of a HANA landscape. If reducing TCO is the goal, shouldn’t all options be considered?
Virtualization has been in heavy use by most customers for years helping to drive up system utilization resulting in the need for fewer systems, decreasing network and SAN ports, reducing floor space and power/cooling and, perhaps most importantly, reducing the cost of IT management. Unfortunately, few high end customers, other than those using IBM Power Systems can take advantage of this technology in the HANA world due to the many reasons identified in the latest of many previous posts.[vi] Put another way, if a customer utilizes an industrial strength and proven virtualization solution for HANA, i.e. IBM PowerVM, they may be able to reduce TCO considerably[vii]and potentially much more than the relatively small improvement due to NVDIMMs.
But if driving down memory costs is the only goal, there are a couple of ideas that are less radical than using NVDIMMs worth investigating. Depending on RTO requirements, some workloads might need an HA option, but might not require it to be ready in minutes. If this is the case, then a cold standby server running other workloads which could be killed in the event of a system outage could be utilized, e.g. QA, Dev, Test, Sandbox, Hadoop. Since no incremental memory would be required, memory costs would be substantially lower than that required for System Replication, even if NVDIMMs are used. IBM offers a tool called VM Recovery Manager which can instrument and automate such a configuration.
Another option worth considering, only for non-production workloads, is a feature of IBM PowerVM called Memory Deduplication. After different VMs are started using “a shared memory pool”, the hypervisor builds a logical memory map. It then scans the pages of each VM looking for identical memory pages at which time it uses the logical memory map to point each VM to the same real memory page thereby freeing up the redundant memory pages for use by other workloads. If a page is subsequently changed by one of the VMs, the hypervisor simply recreates a unique real memory page for that VM. The upshot of this feature is that the total quantity of DRAM memory may be reduced substantially for workloads that are relatively static and have large amounts of duplication between them. The reason that this should not be used for production is because when the VMs start, the hypervisor has not yet had the chance to deduplicate the memory pages and, if the sum of logical memory of all VMs is larger than the total memory, paging will occur. This will subside over time and may be of little consequence to non-production workloads, but the risk to performance for production might be considered unacceptable and, besides, “Memory over-commitment must not be used” for production HANA according to SAP.
Summary
Faster restarts than may be possible with traditional Intel systems may be achieved by using near zero HANA upgrades with System Replication, HANA fast restart or by switching to a system with a radically faster I/O subsystem, e.g. IBM Power Systems. TCO may be reduced with tried and proven virtualization technologies as provided with IBM PowerVM, cold standby systems or memory deduplication rather than experimenting with version 1.0 of a new technology with no track record, unknown reliability, poor guidance on sizing and potentially huge impacts to performance.
[i]https://www.ibm.com/downloads/cas/WQDZWBYJ
[ii]https://launchpad.support.sap.com/#/notes/1984882
[iii]https://help.sap.com/viewer/6b94445c94ae495c83a19646e7c3fd56/2.0.04/en-US/ce158d28135147f099b761f8b1ee43fc.html
[iv]https://launchpad.support.sap.com/#/notes/1984787
[v]https://launchpad.support.sap.com/#/notes/2786237
[vi]https://saponpower.wordpress.com/2018/09/26/vmware-pushes-past-4tb-sap-hana-limit/
Optane DC Persistent Memory – Proven, industrial strength or full of hype – Detail, part 2
If the performance considerations from part 1 were the only issues, a reasonable case could be made for the potential value of doing a PoC with this technology. But, of course, those are not the only issues. One of the reasons that NVDIMMs have longer latencies than DRAM is due to their persistence and therefore the need to encrypt data placed on these components. Encryption and decryption take a lot of computational power and can have a substantial impact on latency and bandwidth. The funny thing is that encryption of these NVDIMMs can be turned off if desired, presumably with a resulting improvement to performance. But what kind of customer would be willing to turn off this vital security technology?
Another desirable trait of modern, in-memory platforms is advanced memory protection which allows a system to continue to operate in the event of a DIMM failure. This often starts with basic ECC, but then progresses to SDDC, DDDC (Chipkill or Lockstep), ADDDC (Skylake and beyond only) and IBM’s unique Chipkill + chip sparing technology. ADDDC is not available for NVDIMMs, but DDDC is. The downside of DDDC is that it comes with a significant performance penalty. No performance numbers have been provided for NVDIMMs configured with DDDC, but previous generations saw 20% to 40% degradation when using this mode.[i][ii]
What kind of customer would be willing to disable key security features or run critical systems without the best available reliability technologies? I would certainly advise customers to use encryption and advanced reliability technologies in most circumstances. Only those customers that can scramble business critical, PII and/or HIPAA data should ever consider disabling persistent memory encryption. I searched, using every option that I could imagine, and failed to find a single web site that recommended ever disabling NVDIMM encryption.
SAP Benchmarks results posted on the external web site do not show the details of how security and reliability configuration parameters have been set. It is therefore impossible to say whether HPE enabled or disabled these protection features. In my many years of experience and extensive discussion with benchmarking experts, I can share that every single one, at every vendor, used every tool or technology that did not violate official rules to enhance results. It would not be too much of a leap to project that HPE, and other vendors posting results with NVDIMMs, have likely disabled anything that might cause their results to diminish in any way. (HPE, if you would like to share your configuration details, I would be happy to post them and if I have mischaracterized how you ran these benchmarks, will also post a retraction.) As a result, these BWH results may not only have relevance to only a small subset of the potential workloads but may also represent an unacceptable exposure to any company that has high single system availability requirements or has one of those unreasonable security departments which thinks that data protection is actually worthwhile.
And then, there are OLTP customers. Based on the lack of benchmark testing of Suite on HANA, S/4HANA or C/4HANA combined with the above data from Lenovo about the massive reduction of bandwidth and associated huge increase in latency for OLTP, it would be MOST unwise to place any of these types of environments on systems with NVDIMMs without extensive testing of real customer workloads to ensure that internal performance SLAs can be met.
Certain types of workloads may perform decently with NVDIMMs. BW environments where the primary use is for predictable and repeatable queries and reports may see only moderate performance degradation compared to DRAM based systems, but still orders of magnitude better performance that AnyDB systems which merely cache recently used data in memory and keep most data on external storage. BW Extension nodes, S/4 Data aging objects and other types of archival systems that take older, less frequently used data and place them on other tiers of storage or systems, could certainly benefit from NVDIMMs. Non-prod workloads which are not in the critical path to production, e.g. dev, test, sandbox, might make sense to place on systems with NVDIMMs. All of these depend on an acceptance of potential performance issues and hardware/firmware/software fixes that inevitably come once customers start playing with version 1.0 of any new technology.
Based on likely performance issues, inferior RAS technology and the above mentioned “fix” dilemma, I would strongly advise that critical systems like production, QA, pre-prod, HA and DR should stay on DRAM based systems until bleeding edge customers prove the value of NVDIMMs and are willing to publicly share their journey.
The question then becomes whether the benefit to a subset of the environments are so substantial that it makes sense to select a vendor for HANA systems based on their ability to utilize NVDIMMs even when this technology might not be used for the most critical of the workloads and their associated critical path and HA/DR systems. This gets into the subjects of cost reduction and restart speeds which will be covered in part 3 of this series.
[i]https://lenovopress.com/lp0048.pdf
[ii]https://sp.ts.fujitsu.com/dmsp/Publications/public/wp-broadwell-ex-memory-performance-ww-en.pdf
Optane DC Persistent Memory – Proven, industrial strength or full of hype – Detail, part 1
Several non-Intel sites suggest that Intel’s storage class memory (Lenovo abbreviates these as DCPMM, while many others refer to them with the more generic term NVDIMM) delivers a read latency of roughly 5 times slower than DRAM, e.g. 350 nanoseconds for NVDIMM vs. 70 nanoseconds for DRAM.[i] A much better analysis comes from Lenovo which examined a variety of load conditions and published their results in a white paper.[ii] Here are some of the results:
- A fully populated 6x DCPMM socket could deliver up to 40GB/s read throughput, 15GB/s write
- Each additional pair of DCPMMs delivered proportional increases in throughput
- Random reads had a load to use latency that was roughly 50% higher than sequential reads
- Random reads had a max per socket (6x DCPMM) throughput that was between 10 and 13GB/s compared to 40 to 45GB/s for sequential reads
The most interesting quote from this section was: “Overall, workloads that are more read intensive and sequential in nature will see the best performance.” This echoes the quote from SAP’s NVRAM white paper: “From the perspective (of) read accesses, sequential scans fare better in NVRAM than point reads: the cache line pre-fetch is expected to mitigate the higher latency.[iii]
The next section is even more interesting. Some of its results comparing the performance differences of DRAM to DCPMM were:
- Almost 3x better max sequential read bandwidth
- Over 5x better max random read bandwidth
- Over 5x better max sequential 2:1 R/W bandwidth
- Over 8x better max random 2:1 R/W bandwidth
- Latencies for DCPMM in the random 2:1 R/W test hit a severe knee of the curve and showed max latencies over 8x that of DRAM at very light bandwidth loads
- DRAM, by comparison, continued to deliver significantly increasing bandwidth with only a small amount of latency degradation until it hit a knee of the curve at over 10x of the max DCPMM bandwidth
Unfortunately, this is not a direct indication of how an application like HANA might perform. For that, we have to look at available benchmarks. To date, none of the SD benchmarks have utilized NVDIMMs. Lenovo published a couple of BWH results, one with and one without NVDIMMs, but used different numbers of records, so they are not directly comparable. HPE, on the other hand, published a couple of BWH results using the exact same systems and numbers of records.[iv] Remarkably, only a small, 6% performance degradation, going from an all DRAM 3TB configuration to a mixed 768GB/3TB NVDIMM configuration occurred in the parallel query execution phase of the benchmark. The exact configuration is not shown on the public web site, but we can assume something about the config based on SAP Note: 2700084 – FAQ: SAP HANA Persistent Memory: “To achieve highest memory performance, all DIMM slots have to be used in pairs of DRAM DIMMs and persistent memory DIMMs, i.e. the system must be equipped with one DRAM DIMM and one NVDIMM in each memory channel.” Vendors submitting benchmark results do not have to follow these guidelines, but if HPE did, then they used 24@32GB DRAM DIMMs and 24@128TB NVDIMMs. Also, following other guidelines in the same SAP Note and the SAP HANA Administration Guide, HPE most likely placed the column store on NVDIMMS with row store, caches, intermediate and final results calculations on DRAM DIMMs.
BWH is a benchmark composed of 1.3 billion records which can easily be loaded into a 1TB system with room to spare. To achieve larger configurations, vendors can load the same 1.3B records a second, third or more times, which HPE did a total of 5 times to get to 6.5B records. The column compression dictionary tables, only grow with unique data, i.e. do not grow when you repeat the same data set regardless of the number of times it is added.
BWH includes 3 phases, a load phase which represents data ingestion from ERP, a parallel query phase and a sequential, single user complex query phase. Some have focused on the ingestion and complex query phases, because they show the most degradation in performance vs. DRAM. While that is tempting, I believe the parallel query phase is of the most relevance. During this phase, 385 queries of low, medium and high complexity (no clue as to how SAP defines those complexities, what their SQL looks like or how many of each type are included) are run, in parallel and randomly. After an hour, the total count of queries completed is reported. In theory, the larger the database, the fewer the queries that could be run per hour as each query would have more data to traverse. However, that is not what we see in these results.
Lenovo, once again, provides the best insights here. With Skylake processors, they reported two results. On the first, they loaded 1.3B records, on the second 5.2B records or 4 times the number of rows with only twice the memory. One might predict that queries per hour would be 4 times or more worse considering the non-proportionate increase in memory. The results, however, show only a little over 2x decrease in Query/hr. Dell reported a similar set of results, this time with Cascade Lake, also with only real memory and also only around 2x decrease in Query/hr for 4X larger number of records.
What does that tell us? It is impossible to say for sure. From the SAP NVRAM white paper referenced earlier, “One can observe that some of the queries are more sensitive to the latency of the persistent memory than others. This can be explained by multiple factors:
- Does the query exhibit a memory access pattern that can easily prefetch by the hardware
- prefetchers? Is the working set of queries small enough to fit in CPU
- cache and hence agnostic to persistent memory latency? Is processing of the query compute or latency bound?”
SAP stores results in the “Static Cache”. “The static result cache is particularly helpful in the following scenario: Complex query based on a view; Rather small result set; Limited amount of changes in the underlying tables. The static result cache can provide the following advantages: Reduction of CPU consumption; Reduction of SAP HANA thread utilization; Performance improvements”[v]
“Other areas like delta storage, caches, intermediate result sets or row store remain solely in dynamic RAM (DRAM) is usually stored in DRAM, not NVDIMMs.[vi]
The data in BWH is completely static. Some queries are complex and presumably based on views. Since the same queries execute over and over again, prefetchers may become especially effective. It may be possible that some or many of the 385 queries in BWH may be hitting the results cache in DRAM. In other words, after the first set of queries run, a decent percentage of accesses may be hitting only the DRAM portion of memory, masking much of the latency and bandwidth issues of NVRAM. In other words, this benchmark may actually be testing CPU power against a set of results cached in working memory more than actual query speed against column store.
So, let us now consider the HPE benchmark with NVDIMMs. On the surface, 6% degradation with NVDIMMs vs. all DRAM seems improbable considering NVDIMM higher latency/lower bandwidth. But after considering the above caching, repetitive data and repeating query set, it should not be much of a shock that this sort of benchmark could be masking the real performance effects. Then we should consider the quote from Lenovo’s white paper above which said that NVDIMMs are a great technology for read intensive, sequential workloads.
Taken together, while not definitive, we can deduce that a real workload using more varied and random reads, against a non-repeating set of records might see a substantially different query throughput than demonstrated by this benchmark.
Believe it or not, there is even more detail on this subject, which will be the focus of a part 2 post.
[i]https://www.pcper.com/news/Storage/Intels-Optane-DC-Persistent-Memory-DIMMs-Push-Latency-Closer-DRAM
[ii]https://lenovopress.com/lp1083.pdf
[iii]http://www.vldb.org/pvldb/vol10/p1754-andrei.pdf
[iv]https://www.sap.com/dmc/exp/2018-benchmark-directory/#/bwh
