IBM Power10 debuts with a new SAP Benchmark!
Today, SAP published a new SD 2-tier result for IBM’s soon to be announced Power E1080.[i] First the highlights:
- 174,000 SD Users
- 955,050 SAPS
- 120 cores
Wait, almost 1M SAPS with only 120 cores? HPE achieved 670,830 SAPS (122,300 users) with 224 cores on their Superdome Flex 280 with the Intel Xeon Platinum 8380H Processor in January, 2021.
This new result is almost 3 times the SAPS/core of HPE’s biggest and baddest system. (Funny note, autocorrect tried to change “baddest” to “saddest”). This new result is also about 33% faster, on a per core basis, than the previous Power 980 result published at the end of 2018. That is certainly not remarkable since Intel’s per core performance on this benchmark also increased about 69.5%, since 2017 … sorry, missed the decimal, 0.695%. (Comparing two Dell 2-socket results, Intel 8180 & Intel 8380).
Clearly, IBM has moved the microarchitecture technology ball forward with a huge improvement in per core performance. And that is significant in that Intel seems to have given up on the microarchitecture game and only seems to be focused on increasing the core count (now up to 40 per socket).
But isn’t the SD benchmark based on ECC 6.0 and primarily an app server benchmark, so do we really care if we are talking about SAP workloads? For that matter, isn’t HANA the name of the game now and how can we correlate this result against HANA workloads?
Yes and you can’t. I will answer the second question first. SAP rules forbid comparisons against different benchmarks and for good reason; they don’t have the same logic, application code, database usage, memory dependency or anything else for that matter. But, we will get to the impact on HANA a bit later in this blog.
The SD benchmark is rather removed from reality both by its age, its dependence on an outdated interface (the old and much loved SAP GUI, not) not to mention old non-HANA databases. Fun fact: since 2005, 96 results are used MaxDB or Sybase, 155 – IBM Db2, 52 – Oracle, 413 – Microsoft SQL and 0 used HANA. And since application servers can easily scale across dozens of systems, the performance per core doesn’t really matter all that much, and this equation usually boils down to $/SAPS.
At Hot Chips 2020, Bill Starke, IBM Power Chief Architect and Brian Thompto, Power10 core architect, revealed a bunch of amazing speeds and feeds including 2.25x the memory bandwidth for Power10 vs Power9 per socket.[ii] We know that HANA eats memory bandwidth for breakfast, lunch, dinner and all snacks in between. This new SD benchmark (and others that IBM will undoubtedly publish very soon) suggest that these new Power processors will be able to handle all workloads, including SAP HANA, with either fewer cores or with the same number of cores and tons of CPU cycles to spare.
It might be tempting to consider using a smaller Power10 system, but this is where the problem gets a bit sticky. HANA not only loves memory bandwidth, but unless you are going to provision a server with less memory than SAP recommends or use one of their tiered approaches, you still need the same quantity of memory regardless of server or microarchitecture. You could certainly reduce the number of cores per socket or go to slower chip speeds and this might be a very good approach for reducing HANA system costs for a lot of customers. Another option to consider is using those spare cycles for something else, after all HANA is supported by SAP for use with IBM PowerVM shared processor pools.
What other workloads might you use those cycles for? We could get into a big discussion about all sort of other workloads, like AI, HPC, etc., but how about we keep this simple? How about for the thing that the SD benchmark actually does test, application serving? Even with S/4HANA and Fiori, you still need application servers. And if you already purchased a server for HANA based on memory requirements and you have a ton of cycles left over, this means that the $/SAPS for those application servers essentially goes toward $0! I have not priced an Intel server lately, but I am pretty certain that the price is not even remotely close to $0.
For existing SAP on Power customers (both HANA and non-HANA), Power10 is going to be amazing, resulting in either better performance, lower cost or both! For customers still trying to decide on which type of system to use, I would strongly encourage a full landscape cost comparison be performed including production HANA and application servers, HA, non-prod and DR.
And as good a news as this is for on-premise customers, cloud vendors that offer HANA on Power, such as IBM, Syntax and SAP, should be even more excited about how they can decrease their costs while offering better solutions to their customers with Power10.
[i] https://www.sap.com/dmc/exp/2018-benchmark-directory/#/sd
[ii] https://www.nextplatform.com/2020/08/18/ibm-brings-an-architecture-gun-to-a-chip-knife-fight/
SAP Extends support for Business Suite 7 to 2027 and beyond … but the devil is always in the detail
The SAP world has been all abuzz since SAP’s announcement on February 4, 2020 about their extension of support for Business Suite 7 (BS7) which many people know as ECC 6.0 and/or related components. According to the press release[i], customers with existing maintenance contracts will be able to continue using and getting support for BS7 through the end of 2027 and will be able to purchase extended maintenance support through the end of 2030 for an additional 2 points over their current contracts.
It is clear that SAP blinked first although, in an interview[ii], SAP positions this as a “proactive step”, not as a reaction to customer pushback. Many tweets and articles have already come out talking about how customers now have breathing room and have clarity on support for BS7. And if I just jumped on the bandwagon here, those of you who have been reading my blog for years would be sorely disappointed.
And now for the rest of the story
Most of you are aware that BS7 is the application suite which can use one of several 3rd party database options. Historically, the most popular database platform for medium to large customers was Oracle DB, followed by IBM Db2. BS7 can also run on HANA and in that context is considered Suite on HANA (SoH).
What was not mentioned in this latest announcement is the support for the underlying databases. For this, one must access the respective SAP Notes for Oracle[iii] and Db2[iv].
This may come as a surprise to some, but if you are running Oracle 12.2.0.1, you only have until November of this year to move to Oracle 19c (or Oracle 18c, but that would seem pretty pointless as its support ends in June of 2021.) But it gets much more fun as that is only supported under normal maintenance until March, 2023 and under extended support until March, 2026. In theory, there might be another version or dot release supported beyond this time, but that is not detailed in any SAP Note. In the best-case scenario, Oracle 12 customers will have to upgrade to 19c and then later to an, as yet unannounced, later version which may be more transition than many customers are willing to accept.
Likewise, for Db2 customers, 10.5, 11.1 and 11.5 are all supported through December, 2025. The good news is that no upgrades are required through the end of 2025.
For both, however, what happens if later versions of either DB are not announced as being supported by SAP. Presumably, this means that a heterogeneous migration to Suite on HANA would be required. In other words, unless SAP provides clarity on the DB support picture, customers using either Oracle DB or IBM Db2 may be faced with an expensive, time consuming and disruptive upgrade to SoH near the end of 2025. Most customers have expressed that they are unwilling to do back to back migrations, so if they are required to migrate to SoH in 2025 and then migrate to S/4HANA in 2027, that is simply too close for comfort.
Lacking any further clarification from SAP, it still seems as if it would be best to complete your conversion to S/4HANA by the end of 2025. Alternately, you may want to ask SAP for a commitment to support your current and/or planned DB for BS7 through the end of 2027, see how they respond and how much they will charge.
[i] https://news.sap.com/2020/02/sap-s4hana-maintenance-2040-clarity-choice-sap-business-suite-7/
[ii] https://news.sap.com/2020/02/interview-extending-maintenance-for-sap-s4hana/
[iii] https://launchpad.support.sap.com/#/notes/1174136
[iv] https://launchpad.support.sap.com/#/notes/1168456
Does Intel’s Optane DC Persistent Memory decrease TCO for SAP?
When this new type of persistent memory DIMM (PMEM) was announced by Intel about a year ago, improving restart times was the most important factor cited by Intel and vendors of systems that utilize Intel Cascade Lake processors. Some of my previous blog posts have discussed the performance issues of PMEM and despite numerous searches, I can find no data presented by Intel or any other vendor to suggest that any improvement has occurred since this technology was made generally available. Over time, and perhaps as more customers realized that faster restarts at the cost of slower operational performance might not be very compelling, the message started to morph into saving money.
Regarding TCO specifically for SAP Suite on HANA (SoH) and S/4HANA, let’s start with the basic assertion, i.e. PMEM is less expensive than DRAM. This is documented by pricing which shows a 128GB PMEM DIMM costs approximately 60% of the cost of a 128 DRAM DIMM[i] on one site and 40%[ii] on another site. This discrepancy may result when one vendor shows effective prices and another list prices with the list price example showing a higher cost savings with PMEM.
I was interested to see what would happen with actual SAP instances. For comparison, let us start with a conventional DRAM memory system and assume that after using appropriate sizing tools, we have determined that an SoH or S/4HANA system requires a total of 6TB of memory to support 3TB of data with 3TB dedicated to system and HANA working memory. I chose 6TB because this fits perfects on most Intel systems using 4 processors and 48@128GB memory DIMMs. This config also has the added bonus of no waste at all and maximized performance since parallelism is optimized when every memory channel is used.
By comparison, we need to figure out how much memory is required if we utilize PMEM. The SAP note on persistent memory[iii] describes ratios of DRAM to PMEM ranging from 2:1 to 1:4. For SoH and S/4HANA, the advice given is to run QuickSizer, /SDF/HDB_SIZING or ZNEWHDB_SIZE depending on where you are starting from. I asked 3 different customers, one small, one medium and one very large, to provide me with the output of their sizing reports based on existing ECC systems. I have included two key sections for the midsized customer:
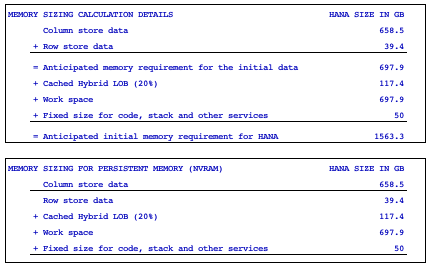
The Persistent Memory FAQ[iv] says: “Persistent memory can be used for the main storage of column store table that is typically the dominating factor of data space consumption in SAP HANA environments. Other areas like delta storage, caches, intermediate result sets or row store remain solely in dynamic RAM (DRAM). Disk LOBs (SAP Note 2220627) are also not part of the persistent memory.” If you add up the numbers above using this rule, you may notice that this means that when using persistent memory, the amount of data housed in PMEM vs. DRAM does not fit with any of the ratios mentioned earlier. Looking at the sizing reports that I obtained, the amount of PMEM vs. DRAM was more in the range of 1:1.5[v].
Now, let’s apply the very best ratio of the three reports, i.e. the very large customer, to our 6TB example above and we see that we need 6TB x .433 = 2.53TB PMEM and 6TB x .567 = 3.47TB DRAM. Assuming 128GB DIMMs, this translates to 20.2 PMEM DIMMs and 27.8 DRAM DIMMs which rounded up comes to 21 and 28 DIMMs, i.e. 49 DIMMs total. Clearly, this is one more than the max number (48) in a 4-socket system. In addition, SAP note 2786237 states that a configuration must have: “Homogeneous symmetrical assembly of DRAM and PMEM DIMMs with maximum utilization of all memory channels per processor”, so the minimum configuration would be 28 of each type of DIMM for a total of 56 DIMM slots.
To the best of my knowledge, no Cascade Lake system supports this number of DIMM slots. Several vendors support 64 DIMM slots on a 6 or 8-socket system. Those that do not would require a 96 DIMM slots configuration. At 64 DIMM slots, this configuration would waste the difference between the HANA memory requirement and the system configuration requirement, i.e. 540GB of DRAM and 1,508GB of PMEM would be wasted. At 96 DIMM slots, the waste would be 2,588GB and 3,556GB respectively. With either a 64 DIMM slot or 96 DIMM slot configuration, instead of a relatively affordable 4-socket system, a significantly more expensive 6 or 8-socket system would be required.
I chose to use the best pricing that I could find for DIMM prices assuming that other vendors would be able to match these prices. I then applied that pricing to those vendors that can utilize 64 DIMM slots on a 6 or 8-socket configuration. After a simple calculation[vi], the cost of just the memory of the DRAM+PMEM system came out $7,648 higher than the DRAM only system. And remember, this is before adding in any additional costs for more processors and a system which can support more processors.
Of course, 256GB DRAM DIMMs could be used, reducing the DRAM DIMM count to 15, but this raises a thorny issue; No appliance has been certified by SAP[vii] with 256GB DRAM DIMMs. Even if we ignored that issue and went out on a limb using TDI V5 relaxed rules, the significantly higher cost of 256GB DRAM DIMMs over 128GB DRAM DIMMs[viii] plus the need to round up to 24 DIMM slots would result in a configuration that was still substantially higher cost than the DRAM only configuration.
Any way that you cut it, the use of PMEM in a realistic SoH or S/4HANA configuration results in a higher cost of acquisition than a DRAM only configuration. In other words, as shown in the previous blog posts, performance takes a major hit when using PMEM for HANA, it does not save any money and actually costs more and the only potential gain comes from faster restarts.
[i] https://www.dell.com/en-us/work/shop/cty/pdp/spd/poweredge-r940/pe_r940_12229_vi_vp?configurationid=0163c707-0003-46a0-808a-3b55c864ba70
[ii] https://dcsc.lenovo.com/#/configuration/cto/7X13CTO1WW?hardwareType=server
[iii] https://launchpad.support.sap.com/#/notes/2786237
[iv] https://launchpad.support.sap.com/#/notes/2700084
[v] actual range was 41.5% to 43.3% for PMEM versus 58.5% to 56.7% for DRAM based on the small to very large reports
[vi] 48 x $2,670 = 128,160 (DRAM only), 32 x $1,574 + 32 x $2,670 = $135,808 (DRAM + PMEM)
[vii] https://www.sap.com/dmc/exp/2014-09-02-hana-hardware/enEN/appliances.html#viewcount=100
[viii] https://dcsc.lenovo.com/#/configuration/cto/7X13CTO1WW?hardwareType=server
Scale-up vs. scale-out architectures for SAP HANA – part 2
S/4HANA is enabled for scale-out up to 4 nodes plus one hot-standby. Enablement does not mean it is easy or advisable. SAP states clearly: “We recommend using scale-up configurations as long as this is economically justifiable, taking operational costs and drawbacks into account.”[i] This same note goes on to say: “Limited knowledge about S/4HANA customer scenarios using scale-out is currently available.”
For very large customers, e.g. those for which an S/4HANA system’s memory is predicted to be larger than 24TB currently, scale-out may be the best option. Best, of course, implies that there may be other options which will be discussed later in this post.
It is a reasonable question to ask why does SAP offer such conditional advice. We can only speculate since SAP does not provide a direct explanation. Some insight may be gained by reading the SAP note on scale-out sizing.[ii] Unlike analytical applications such as BW/4HANA, partitioning of S/4HANA tables across nodes is not permitted. Instead, all tables of a particular module are grouped together and the entire group must be placed on an individual node in the cluster.
Let’s consider a simple example of three commonly used modules, FI, MM and SD (Financial, Materials, Sales). The tables associated with each module belong to their respective groups. Placing each on a different node may help to minimize the size of any one node, but several issues arise.
- Each will probably be a different size. This fully supported, but the uneven load distribution may result in one node running at high utilization while another is barely using any capacity. Not only does this mean wasted computing power, power and cooling but could result in inferior performance on the hot node.
- Since most customers prefer to size all nodes in a cluster the same way, considerable over capacity of memory might result further driving up infrastructure costs.
- Transactions often do not fit comfortably within a single module, e.g. a sales order might result in financial tables being updated with billing, accounts receivable and revenue data and materials tables being adjusted with a decrement of available stock. If a transaction is running on node 1 (the master node) and needs to access/update tables on nodes 2 and 3, those communications run across a network. As with the BW example in the previous blog post, each communication is at least 30 times slower across a network than across memory.
It is important to consider that every transaction that comes into an S/4HANA system connects to the index server on the master node with queries distributed by the master node to the appropriate index server. This means that every transaction not handled directly by the master node must involve at least one send and one receive with the associated 30 times slower latency.
Some cross-node latency may be reduced by collocating appropriate groups resulting in fewer total nodes and/or by replicating some tables. Unfortunately, if a table is replicated, this would result in the breaking of a fundamental SAP rule noted in SAP Note 2408419 (see footnote #1 below), that all tables of a group must be located on the same node.
As with the BW example, what works well for one scenario may not work well for another. One of the significant advantages of S/4HANA over Business Suite 7 is the consolidation and dramatic reduction of tables resulting in fewer, much larger tables. Conversely, this makes table distribution in a scale-out cluster much more challenging. It is not hard to imagine that performance management could be quite a task in a scale-out scenario.
So, if scale-out is not an option for many/most customers, what should be done if approaching a significant memory barrier? Options include:
- Cleanup, use of hybrid LOBs, index optimization, etc
- Archiving data to reduce the size of the system
- Eliminating duplicate data or easily reproduced data, e.g. iDocs, data from Hadoop
- Usage of Data Aging[iii]
- Sizing memory smaller than predicted
- Request an exception to size the system larger than officially supported
Cleaning up your system and getting rid of various unnecessary memory consumers should be the first approach undertaken.[iv] Remember, what might have been important with a conventional DB may either be not needed with S/4HANA or a better technique may exist. The expected memory reduction is usually shown as part of an ERP sizing report.
Archiving is another obvious approach but since the data is kept on very slow media, compared to in-memory data, and cannot be changed, the decision as to what to archive and where to place it can be very challenging for some organizations.
iDocs are, by definition, intermediate documents and are used primarily for sending and receiving documents to/from third parties, e.g. sales orders, purchase orders, invoices, shipping notices. Every iDoc sent or received should have a corresponding transaction within the SAP system which means that it is essentially a duplicate record once processed by the SAP system. Many customers keep these documents indefinitely just in case any disputes occur with those third parties. Often, these iDocs just sit around collecting digital dust and may be prime candidates for deletion or archival. Likewise, data from an external source, e.g. Hadoop, should still exist in that source and could potentially be deleted from HANA.
Data Aging only covers a subset of data objects and requires some effort to utilize it.[v] By default, the ABAP server adds “WITH RANGE RESTRICTION (‘CURRENT’)” to all queries to prevent unintended access to aged or cold partitions, which means that to access aged data, a query must specify which aged partition to access. This implies special transactions or at least different training for users to access aged data. Data Aging does allow aged data to be updated, so may be more desirable than archiving in some cases. Aged data is stored on storage devices which means many order of magnitude slower than memory, however this can be mitigated, to some extent by faster media, e.g. NVMe drives on PCIe cards. Unfortunately, Data Aging has not been implemented by many customers meaning a potentially steep learning curve.
Deliberately undersizing a system is not recommended by SAP and I am not recommending it either. That said, if an implementation is approaching a memory boundary and scaling to a larger VM or platform is not possible (physically, politically or financially), then this technique may be considered. It comes with some risk, however, so should be considered a last resort only. HANA enables “lazy loading” of columns[vi] whereby columns are not loaded until needed. If your system has a large number of columns which consume space on disk but are never or rarely accessed, the memory reserved for these columns will, likewise, go unused or underused. HANA also will attempt to unload columns when the system runs out of allocable memory based on a least frequently used algorithm. Unless a problem occurs, a system configured with less memory than the sizing report predicts will start without problem and unload columns when needed. The penalty comes when those columns that are not memory resident are accessed at which time other column(s) must first be unloaded and the entire requested column loaded, i.e. significant latency for the first access is incurred. As mentioned earlier, this should be considered only in a worst case scenario and only if scaling up/out is not desired or an option.
Lastly, requesting an exception from SAP to allow a system size greater than officially supported may be a viable choice for the customers that are expected to exceed current maximums. This may not be without difficulty as when you embark on a journey where few or none have gone before, inevitably, you will run into obstacles that others have not yet encountered. Dispatch mechanisms, delta merge operations, transactional log latency, savepoint I/O throughput, system startup times, backup/recovery and system replication are among some of the more significant areas that would be stressed and some might break.
My advice: Scale-up only in all S/4HANA cases unless the predicted memory for the immediate planning horizon exceeds the official SAP maximum supported size. Before considering scale-out solutions, use every available tool to reduce the size of the system and ask SAP for an exception if the resulting size is still above the maximum. Lastly, remember that SAP and its hardware partners are constantly working to enable larger HANA system sizes. If the size required today fits within the largest supported system but is expected to exceed the limit over time, it may be reasonable to start your implementation or migration effort today with the expectation that the maximum will be increased by the time you need it. Admittedly, this is taking a risk, but one that may be tolerable and if the limit is not raised in time, scale-out is still an option.
[i]2408419 – SAP S/4HANA – Multi-Node Support
[ii]2428711 – S/4HANA Scale-Out Sizing
[iii]2416490 – FAQ: SAP HANA Data Aging in SAP S/4HANA
[iv]1999997 – FAQ: SAP HANA MemoryFAQ 5
[v]1872170 – Business Suite on HANA and S/4HANA sizing report.
[vi]https://www.sap.com/germany/documents/2016/08/205c8299-867c-0010-82c7-eda71af511fa.html
Power Systems – Delivering best of breed scalability for SAP HANA
SAP quietly revised a SAP Note last week but it certainly made a loud sound for some. Version 47 of https://launchpad.support.sap.com/#/notes/2188482 now says that OLTP workloads, such as Suite on HANA or S/4HANA are now supported on IBM Power Systems up to 24TB. OLAP workloads, like BW HANA may be implemented on IBM Power Systems with up to 16TB for a single scale-up instance. As noted in https://launchpad.support.sap.com/#/notes/2055470, scale-out BW is supported with up to 16 nodes bringing the maximum supported BW environment to a whopping 256TB.
As impressive as those stats are, it should also be noted that SAP also provided new core-to-memory (CTM) guidance with the 24TB OLTP system sized at 176-cores which results in 140GB/core, up from the previous 113.7GB/core at 16TB. The 16TB OLAP system, sized at 192-cores, translates to 85.3GB/core, up from the previous 50GB/core for 4-socket and above systems.
By comparison, the maximum supported sizes for Intel Skylake systems are 6TB for OLAP and 12TB for OLTP which correlates to 27.4GB/core OLAP and 54.9GB/core OLTP. In other words, SAP has published numbers which suggest Power Systems can handle workloads that are 2.7x (OLAP) and 2x (OLAP) the size of the maximum supported Skylake systems. On the CTM side, this works out to a maximum of 3.1x (OLAP) and 2.6x (OLTP) better performance per core for Power Systems over Skylake.
Full disclosure, these numbers do not represent the highest scaling Intel systems. In order to find them, you must look at the previous generation of systems. Some may consider them obsolete, but for customers that must scale beyond 6TB/12TB (OLAP/OLTP) and are unwilling or unable to consider Power Systems, an immediate sunk investment may be their only choice. (Note to customers in this undesirable predicament, if you really want to get an independent, third party verification of potential obsolesence, ask your favorite leasing companies, not associated or owned by the vendor, what residual value they would assume after 1 year for these systems vs. what they would assume for similar Skylake systems after 1 year.)
The previous “generation” of HPE Superdome, “X”, which as discussed in my last blog post shares 0% technology with Skylake based HPE Superdome “Flex”, was supported up to 8TB/16TB with 384 cores for both OLAP and OLTP, resulting in CTM of 21.3GB/42.7GB/core. The SGI derived HPE MC990 X, which is the real predecessor to the new “Flex” system, was supported up to 4TB/20TB with 192 cores OLAP with 480 cores.
Strangely, “Flex” is only supported for HANA with 2 nodes or chassis where “MC990 X” was supported with up to 5 nodes. It has been over 4 months since “Flex” was announced and at announcement date, HPE loudly proclaimed that “Flex” could support 48TB with 8 chassis/32 sockets https://news.hpe.com/hewlett-packard-enterprise-unveils-the-worlds-most-scalable-and-modular-in-memory-computing-platform/. Since that time, some HPE reps have been telling customers that 32TB support with HANA was imminent. One has to wonder what the hold up is. First it took a couple of months just to get 128GB DIMM support. Now, it is taking even longer to get more than 2-node support for HANA. If I were a potential HPE customer, I would be very curious and asking my rep about these delays (and I would have my BS detector set to high sensitivity).
Customers have now been presented with a stark contrast. On one side, Power Systems has been on a roll; growing market share in HANA, regular increases in supported memory sizes, the ability to handle the largest single image HANA memory sizes of any vendor, outstanding mainframe derived reliability and radically better flexibility with built in virtualization and support for a maximum of 8 concurrent production HANA instances or 7 production with many dozens of non-prod HANA, application servers, non-HANA DBs and/or a wide variety of other applications supported in a shared pool, all at competitive price points.
On the other hand, Intel based HANA systems seem to be stuck in a rut with decreased maximum memory sizes (admittedly, this may be temporary), anemic increases in CTM, improved RAS but not yet to the league of Power Systems and a very questionable VMware based virtualization support filled with caveats, limitations, overhead and poor, at best, sharing of resources.
HPE Superdome is dead, but HPE marketing continues its deceptive ways.
Today, 11/6/17, HPE announced the “New” Superdome Flex. If you did not look too closely, you would think that this was some sort of descendant of Superdome. After all, the Integrity Superdome took the original Superdome and replaced PA-RISC chips and the SX1000 cell controller with Itanium chips and a faster SX2000 cell controller. Superdome 2 took this further by upgrading to the latest Itanium chips, an even faster SX3000 cell controller and moved from a cell board to a blade configuration. Superdome X changed out the Itanium chips for Intel Xeon chips which it upgraded over several generations. So, it would be only natural to think that Superdome Flex did something similar and that is exactly what HPE wants you to think.
Except, this is not even remotely like any prior Superdome and has inherited almost nothing from it. In fact, this is a very straightforward descendant of the SGI UV 300H, which HPE renamed the MC990 X after the acquisition. A glance at the front of the “new” system shows the same basic design, a 4-socket, 5U chassis even down to the unique diagonal handles on the fans, but they apparently moved the NUMAlink fabric ports (no longer called that; renamed Superdome Flex ports) from the back to the front, perhaps to get rid of a little of the rats nest of cables which defined the SGI UV 300H. This means there is no SX3000 or cross bar switch in the Flex and the blade design is gone. Even the memory DIMMS are different which implies that nothing could be moved from an old Superdome X to a new “Flex” other than perhaps some old PCIe adapters.
So, if the entire design is based on an SGI acquired technology and it shares nothing from its “namesake”, one would need to avoided that course in ethics in high school or college to find it appropriate to suggest to customers that this is a related technology. Imagine if Honda changed the engine, frame, transmission, trim and body style but called their new car an Accord “Flex” because it used the same bumper and tire sizes, would you feel as if they were trying to manipulate you?
Back to the more important topic, Superdome is now dead! I have been saying this for a while and blogged about this several months ago. I suggested that any customer considering investing in this technology view it as instantly obsolete and a sunk investment. I pointed out the huge investment in ccNUMA interconnect technologies and how it was hard to imagine how HPE could afford to invest in 2 different ones at the same time, so only one system was likely to survive. I explained that the SGI technology offered more space and power to host the new, larger, higher wattage and heat dissipating Skylake processors. It appears that my projections were correct. For customers that ignored that advice, I just hope you got a really great price and don’t mind paying a lot for old technology for any upgrades or dumping your old systems at a huge financial loss. For any customer still considering a Superdome X, the writing is no longer on the wall. It is on HPE’s web site. https://news.hpe.com/hewlett-packard-enterprise-unveils-the-worlds-most-scalable-and-modular-in-memory-computing-platform/
Currently, no white papers have been published showing the architecture and detailed specs of this “new” system, only a relatively high level “Spec” sheet. Perhaps HPE is too embarrassed to publish this since it would likely resemble the SGI UV 300H in way too many ways, including the old rats nest of 4-bit wide interconnect cables. Once they do, I will investigate and will likely publish a separate post to share what I find.
On the SAP front, new HANA appliance specs have been published for “Flex”. It is interesting, and again embarrassing for HPE, that only up to 8-socket configs are shown, with less BWoH memory support @ 6TB max than the old, and now obsolete, Superdome X. Even more interesting is the lack of SoH and S/4 configs, and I have a suspicion as to why. Turns out that the spec sheet does have one interesting point after all. It shows the maximum size memory DIMMS are 64GB and the number of DIMMS slots is 48 with a max supported memory of 3TB per chassis, i.e. half of what is necessary to support the 6TB per 4-sockets that other competing Intel vendors support.
So, if you need a supported HANA configuration today with current generation processors for BWoH beyond 6TB, look at any vendor other than HPE with 8-socket Skylake systems or IBM Power Systems. If you need a supported SoH or S/4 configuration with current gen processors, look at any vendor other than HPE and beyond 12TB, only IBM Power Systems is supported at this level.
TDI Phase 5 – SAPS based sizing bringing better TCO to new and existing Power Systems customers
SAP made a fundamental and incredibly important announcement this week at SAP TechEd in Las Vegas: TDI Phase 5 – SAPS based sizing for HANA workloads. Since its debut, HANA has been sized based on a strict memory to core ratio determined by SAP based on workloads and platform characteristics, e.g. generation of processor, MHz, interconnect technology, etc. This might have made some sense in the early days when much was not known about the loads that customers were likely to experience and SAP still had high hopes for enabling all customer employees to become knowledge workers with direct access to analytics. Over time, with very rare exception, it turned out that CPU loads were far lower than the ratios might have predicted.
I have only run into one customer in the past two years that was able to drive a high utilization of their HANA systems and that was a customer running an x86 BW implementation with an impressively high number of concurrent users at one point in their month. Most customers have experienced just the opposite, consistently low utilization regardless of technology.
For many customers, especially those running x86 systems, this has not been an issue. First, it is not a significant departure from what many have experienced for years, even those running VMware. Second, to compensate for relatively low memory and socket-to-socket bandwidth combined with high latency interconnects, many x86 systems work best with an excess of CPU. Third, many x86 vendors have focused on HANA appliances which are rarely utilized with virtualization and are therefore often single instance systems.
IBM Power Systems customers, by comparison, have been almost universal in their concern about poor utilization. These customers have historically driven high utilization, often over 65%. Power has up to 5 times the memory bandwidth per socket of x86 systems (without compromising reliability) and very wide and parallel interconnect paths with very low latencies. HANA has never been offered as an appliance on Power Systems, instead being offered only using a Tailored Datacenter Infrastructure (TDI) approach. As a result, customers view on-premise Power Systems as a sort of utility, i.e. that they should be able to use them as they see fit and drive as much workload through them as possible while maintaining the Service Level Agreements (SLA) that their end users require. The idea of running a system at 5%, or even 25%, utilization is almost an affront to these customers, but that is what they have experienced with the memory to core restrictions previously in place.
IBM’s virtualization solution, PowerVM, enabled SAP customers to run multiple production workloads (up to 8 on the largest systems) or a mix of production workloads (up to 7) with a shared pool of CPU resources within which an almost unlimited mix of VMs could run including non-prod HANA, application servers, as well as non-SAP and even other OS workloads, e.g. AIX and IBM i. In this mixed mode, some of the excess CPU resource not used by the production workloads could be utilized by the shared-pool workloads. This helped drive up utilization somewhat, but not enough for many.
These customers would like to do what they have historically done. They would like to negotiate response time agreements with their end user departments then size their systems to meet those agreements and resize if they need more capacity or end up with too much capacity.
The newly released TDI Overview document http://bit.ly/2fLRFPb describes the new methodology: “SAP HANA quicksizer and SAP HANA sizing reports have been enhanced to provide separate CPU and RAM sizing results in SAPS”. I was able to verify Quicksizer showing SAPS, but not the sizing reports. An SAP expert I ran into at TechEd suggested that getting the sizing reports to determine SAPS would be a tall order since they would have to include a database of SAPS capacity for every system on the market as well as number of cores and MHz for each one. (In a separate blog post, I will share how IBM can help customers to calculate utilized SAPS on existing systems). Customers are instructed to work with their hardware partner to determine the number of cores required based on the SAPS projected above. The document goes on to state: “The resulting HANA TDI configurations will extend the choice of HANA system sizes; and customers with less CPU intensive workloads may have bigger main memory capacity compared to SAP HANA appliance based solutions using fixed core to memory sizing approach (that’s more geared towards delivery of optimal performance for any type of a workload).”
Using a SAPS based methodology will be a good start and may result in fewer cores required for the same workload as would have been previously calculated based on a memory/core ratio. Customers that wish to allocate more of less CPU to those workloads will now have this option meaning that even more significant reduction of CPU may be possible. This will likely result in much more efficient use of CPU resources, more capacity available to other workloads and/or the ability to size systems with less resources to drive down the cost of those systems. Either way helps drive much better TCO by reducing numbers and sizes of systems with the associated datacenter and personnel costs.
Existing Power customers will undoubtedly be delighted by this news. Those customers will be able to start experimenting with different core allocations and most will find they are able to decrease their current HANA VM sizes substantially. With the resources no longer required to support production, other workloads currently implemented on external systems may be consolidated to the newly, right sized, system. Application servers, central services, Hadoop, HPC, AI, etc. are candidates to be consolidated in this way.
Here is a very simple example: A hypothetical customer has two production workloads, BW/4HANA and S/4HANA which require 4TB and 3TB respectively. For each, HA is required as is Dev/Test, Sandbox and QA. Prior to TDI Phase 5, using Power Systems, the 4TB BW system would require roughly 82-cores due to the 50GB/core ratio and the S/4 workload would require roughly 33 cores due to the 96GB/core ratio. Including HA and non-prod, the systems might look something like:

Note the relatively small number of cores available in the shared pool (might be less than optimal) and the total number of cores in the system. Some customers may have elected to increase to an even larger system or utilize additional systems as a result. As this stood, this was already a pretty compelling TCO and consolidation story to customers.
With SAPS based sizing, the BW workload may require only 70 cores and S/4 21 cores (both are guesses based on early sizing examples and proper analysis of the SAP sizing reports and per core SAPS ratings of servers is required to determine actual core requirements). The resulting architecture could look like:

Note the smaller core count in each system. By switching to this methodology, lower cost CPU sockets may be employed and processor activation costs decreased by 24 cores per system. But the number of cores in the shared pool remains the same, so still could be improved a bit.
During a landscape session at SAP TechEd in Las Vegas, an SAP expert stated that customers will be responsible for performance and CPU allocation will not be enforced by SAP through HWCCT as had been the case in the past. This means that customers will be able to determine the number of cores to allocate to their various instances. It is conceivable that some customers will find that instead of the 70 cores in the above example, 60, 50 or fewer cores may be required for BW with decreased requirements for S/4HANA as well. Using this approach, a customer choosing this more hypothetical approach might see the following:

Note how the number of cores in the shared pool have increased substantially allowing for more workloads to be consolidated to these systems, further decreasing costs by eliminating those external systems as well as being able to consolidate more SAN and Network cards, decreasing computer room space and reducing energy/cooling requirements.
A reasonable question is whether these same savings would accrue to an x86 implementation. The answer is not necessarily. Yes, fewer cores would also be required, but to take advantage of a similar type of consolidation, VMware must be employed. And if VMware is used, then a host of caveats must be taken into consideration. 1) overhead, reportedly 12% or more, must be added to the capacity requirements. 2) I/O throughput must be tested to ensure load times, log writes, savepoints, snapshots and backup speeds which are acceptable to the business. 3) limits must be understood, e.g. max memory in a VM is 4TB which means that BW cannot grow by even 1KB. 4) Socket isolation is required as SAP does not permit the sharing of a socket in a HANA production/VMware environment meaning that reducing core requirements may not result in fewer sockets, i.e. this may not eliminate underutilized cores in an Intel/VMware system. 5) Non-prod workloads can’t take advantage of capacity not used by production for several reasons not the least of which is that SAP does not permit sharing of sockets between VM prod and non-prod instances not to mention the reluctance of many customer to mix prod and non-prod using a software hypervisor such as VMware even if SAP permitted this. Bottom line is that most customers, through an abundance of caution, or actual experience with VMware, choose to place production on bare-metal and non-prod, which does not require the same stack as prod, on VMware. Workloads which do require the same stack as prod, e.g. QA, also are usually placed on bare-metal. After closer evaluation, this means that TDI Phase 5 will have limited benefits to x86 customers.
This announcement is the equivalent of finally being allowed to use 5th gear on your car after having been limited to only 4 for a long time. HANA on IBM Power Systems already had the fastest adoption in recent SAP history with roughly 950 customers selecting HANA on Power in just 2 years. TDI Phase 5 uniquely benefits Power Systems customers which will continue the acceleration of HANA on Power. Those individuals that recommended or made decisions to select HANA on Power will look like geniuses to their CFOs as they will now get the equivalent of new systems capacity at no cost.
Intel Skylake has been announced and the self-described HANA “market leader”, HPE, is curiously trailing the field
Intel announced general availability of their “Skylake” processor on the “Purely” platform last week. Soon after, SAP posted certified HANA configurations for Lenovo and Fujitsu up to 8 sockets and 12TB memory for Suite on HANA (SoH) and S/4HANA (S4) and 6TB for BW on HANA (BWoH). They also posted certified configurations for Dell and Cisco up to 4-socket systems with 6TB SoH/S4 and 3TB BWoH. The certified configurations posted for HPE, which describes itself as the HANA market leader, only included up to 4-socket/3TB BWoH configurations, no configurations for SoH/S4 and nothing for any larger systems.
It is still early and more certified configurations will no doubt emerge over time, but these early results do beg the question, “what is going on with HPE?” I checked the most recent press releases for HPE and they did not even mention the Skylake debut much less their certification with SAP HANA. If you Google using the keywords, HPE, Skylake and HANA, you may find a few discussions about HPE’s acquisition of SGI and my previous blog posts with my speculation about Superdome’s demise and HPE’s misleading of customers about this impending event, but nothing from HPE.
So, I will share a little more speculation as to what this slow start for HPE in the Skylake space might portend.
Option 1 – HPE is not investing the funds necessary to certify all of their possible configurations and SoH/S4. Anyone that has been involved with the HANA certification process will tell you that it is very time consuming and expensive. As you can see from HPE’s primary Intel based competitors, they are all very eager to increase their market share and acted quickly. Is HPE becoming complacent? Are they having financial restrictions that have not been made public?
Option 2 – HPE’s technology limitations are becoming apparent. The Converged System 500 is based on Proliant DL560/580 systems which support a maximum of 4 sockets. These systems utilize Intel QPI and now UPI interconnect technologies, i.e. no custom ASICs or ccNUMA switches are required. The CS900 based on the Superdome X and the MC990 X (SGI UV 300H) utilize custom ASICs and, in the case of Superdome X, a set of ccNUMA switches. As I speculated previously, Superdome X is probably at end of life, so it may never see another certification on SAP’s HANA site. As to the MC990 X, the crystal ball is a bit more hazy. Perhaps HPE is trying to shoot for the moon and hit a number beyond the 20TB for SoH/S4 that is currently supported meaning a much longer and more complex set of certification tests. Or perhaps they are running into technical challenges with the new ASICs required to support UPI.
Option 3 – MC990 X is going to officially become HPE’s only high end offering to support Skylake and subsequent processors and Superdome X is going to be announced at end of life. If this were to happen, it would mean that anyone that had recently purchased such a system would have purchased a system that is immediately obsolete.
If Option 1 turns out to be true, one would have to concerned about HPE’s future in the HANA space. If Option 2 turns out to be true, one would have to be really concerned about HPE’s future in the HANA space. And if Option 3 turns out to be true, why would HPE be waiting? The answer may be inventory. If HPE has a substantial inventory of “old” Broadwell based blades and Superdome X chassis, they will undoubtedly want to unload these at the highest price possible and they know that the value of obsolete systems after such an announcement would drop into the below cost of manufacturing range.
So, you pick the most likely scenario. Worst case for HPE is that they are just a little slow or shooting too high. Worst case for customers is that they purchase a HANA system based on Superdome X and end up with a few hundred thousand dollar boat anchor. If you work for a company considering the purchase of an HPE Superdome X solution, you may want to ask about its future and, if you find it is at end of life, select another solution for your SAP HANA requirements.
Inevitably, more systems will be published on SAP’s certification page, https://www.sap.com/dmc/exp/2014-09-02-hana-hardware/enEN/appliances.html#viewcount=100&categories=certified%2CIntel%20Skylake%20SP . When that happens, especially if any of my predictions turn out to be true or if they are all wrong and another scenario emerges, I will post an update.
HPE, in an act of desperation, is spreading misinformation about SAP HANA on IBM Power Systems
Misinformation is a poor characterization of HPE’s behavior. HPE, or some of its employees, are showing customers charts with a variety of statements which are simply untrue. In any normal definition, this is called a lie. This is unethical and unprofessional. I will repeat what it says in my profile, these are my opinions, not a reflection of those of IBM.
You may have seen the blog post from Vicente Moranta: https://www.linkedin.com/pulse/truth-wild-lies-being-told-hanaonpower-vicente-moranta or my own post on IBM Systems Blog: https://www.ibm.com/blogs/systems/can-you-tell-hana-on-ibm-power-systems-fact-from-fiction/ . At IBM, we have this set of ethical rules called “IBM Business Conduct Guidelines” (BCG). This 15 to 20 page document is required reading every year with a mandatory test to ensure comprehensive understanding of these rules. I can boil down one of the most important themes into two words: DON’T LIE!
For those of you who have been reading this blog for a while, you may question whether I am too verbose and that may be fair as I thoroughly research each subject and include attribution for claims, usually including direct links to the source of those claims. I would never think of making up “facts” and, on rare occasion when a reader has informed me of a mistake, I always correct the mistake as well as include a comment to that effect.
Some background: A few weeks ago, a customer sent us a list of questions about SAP HANA on IBM Power Systems. At first, the questions seemed bizarre as they included some very pointed misunderstandings about HANA and SAP in general and IBM’s role with SAP in particular. As I read them more thoroughly, I realized that someone or some entity had coached the customer. This was confirmed when I received a copy of a HPE presentation from a completely different source with almost identically worded statements. By the way, back to the BCG, IBM employees are not allowed to view much less share information from a competitor marked confidential and this presentation was not marked with anything, meaning it was being shown to customers with, or without, HPE management’s official knowledge.
Some of the lies it shares:
- HPE has 99%+ share of the HANA market. It is kind of funny to note that this claim is contradicted in the same table where it shows 80% share for Intel. I guess they are confusing SAP and SAP HANA markets which is misleading at best. More importantly, SAP does not release market share information and even if they did, I think the Lenovo, Cisco, Dell and Fujitsu might together claim more than 1% of the market.
- IBM, not SAP “delivers” HANA code to customers because they have access to SAP code and have created a “special” version of SAP HANA. Wow, it is hard to figure out where to start here. SAP owns HANA and only they distribute code. They refused to support other operating systems than Linux, including AIX, for the very reason of wanting a common code tree for all platforms. HPE is correct that IBM works closely with SAP to optimize HANA code, a fact which should be lauded not criticized. Apparently, HPE must not have such a relationship and are jealous? What HPE does not understand is that regardless of who, IBM, Intel or other, contributes code to SAP or suggests modifications to code, SAP makes all decisions regarding that code, including support, and incorporates it into the common code tree meaning all platforms can benefit if the code is not related to a specific, proprietary instruction set. When Intel contributed code for TSX, Power HANA was not able to use this code, but with appropriate modifications, SAP was able to add the code to call IBM’s similar “Transactional Memory” calls. Now, there is simple logic which ensures the appropriate call is made depending on the underlying processor architecture. Likewise, when IBM saw that the huge number of threads in its architecture might push limits in HANA, it worked with SAP to improve the thread and workload dispatch mechanisms in HANA. When Intel released their Broadwell-EX 24-core chips and SAP approved large socket counts, these systems would have hit the same threading issues, but with the new mechanisms already in place, were able to benefit from IBM & SAP’s joint effort. Maybe HPE means that SAP has to compile the same code as used for Intel systems on the Power platform. Well duh, it is a different chip architecture, so this is computer science 101, but hardly a different “version”.
- Release priority – #1 Intel, #2 Power. Wrong again HPE! HANA 2.0 released simultaneously on Intel and Power, as they did for S/4HANA 1610 on-prem edition, support for SoH with HANA 2.0, etc. Where do you get your misinformation HPE? This information is widely available on SAP’s Service Marketplace and the SAP PAM.
- Sizes supported – HPE shows Power support of “only” 4.8TB for BW, 9TB for SoH vs. 24TB for Intel and No scale-out HANA on Power – I will give HPE the benefit of the doubt on the 4.8TB statement as 6TB just came out, but the “only” part is strange in that in the same table it shows “only” 4TB support on Intel. As to 9TB SoH and lack of scale-out HANA, both are wrong and have been for a while with 16TB SoH available since December 4th, 2016, see SAP Note 2188482 and scale-out HANA since November 2015. As to the 24TB claim for Intel, the largest supported HANA appliance is 20TB, so HPE, once again, seems to be making up facts.
There were other lies, but I think you get the idea. Here are a few suggestions:
To HPE management: Shame on you for permitting such behavior or if done with your knowledge, for encouraging it. If you have any “integrity” (pun intended), you will fire the employees and managers responsible for knowingly spreading lies and will print a retraction in appropriate press sources and on your web site. If you don’t, then you are demonstrating, loud and clear, that your company is not to be trusted.
To HPE employees: Unless your management takes the above suggestions to heart with appropriate action to rectify this wrong, I am not sure how you can sleep well working for a company that considers truth to be something to be sacrificed at their convenience. Hope they are truthful about your benefits.
To SAP customers: I can only speak for myself; when a restaurant, retailer or manufacturer lies to me and/or the public, I refuse to ever do business with them again. The old saying applies, “fool me once, shame on you, fool me twice, shame on me.” When you consider the minimal differences, if any, in cost of acquisition between all HANA system providers on the market, including IBM Power
Is your company ready to put S/4HANA into the Cloud? – part 4
This is the 4th and final installment on this topic. Sorry for the length of each part, but the issues surrounding placement of corporate application environments cannot be boiled down into simple statements like “always think cloud first” or “cloud is no place for a corporate application”.
- How will you get from your current on-premise SAP landscape to the cloud? As mentioned in a recent blog post[i], database conversions from a conventional database or Suite on HANA to S/4HANA are not trivial to start with. Now add the complexity of doing that across a WAN with system characteristics and technologies which you may not be able to control and you have just made a difficult task even more so.
- Can a migration be completed within the outage window that your business allows? Fundamentally, the business will only allow outages which result in little to know lost business or financial penalties. Where you may be able to use dedicated, 1Gb or 10Gb Ethernet or even faster internal networks (in the case of Power Systems), unless you are able to purchase temporary, massive WAN bandwidth, you may be faced with an outage that is longer than the business will allow.
- At what cost, complexity and risk? If such a migration would take longer than allowable, there are strategies and solutions to deal with this, e.g. SAP MDS (Minimized Downtime Service), IBM CDC (InfoSphere Change Data Capture), SNP Transformation Backbone, Dell Shareplex, but these add cost, require much more planning and testing and might impose some additional risk especially across WAN communications, see the discussion on security across the WAN above.
Lest you feel that this post is overly focused on issues which might prevent you from moving to the cloud, there are good reasons as well. As I am not an expert on that part of the story, I will refer you to some pretty good articles on the subject.[ii] The common theme across these sites is that cloud can a) result in cost savings, b) improve agility, c) provide more elasticity and scaling, d) move from a CapEx model to OpEx. Lets take these one at a time.
a) cost savings – For customers that are growing rapidly, are startups, have never implemented a complex ERP system, Cloud certainly can offer major cost avoidance. For customers with existing data centers, Linux or Unix trained support staffs, UPS and diesel generator power units, storage, security and operations standards, investments and teams, backup and recovery solutions, unless the move of SAP to the cloud along with other potential moves will allow for a large portion of those staffs to be laid off and data centers sold to another company, it may be more challenging to figure out exactly what sort of savings result from a move to the cloud. Once you address all of your corporate requirements, discussed in detail in parts 2 and 3 of this blog, a new price for the cloud services to support your SAP S/4HANA environment may emerge and then you can start the process of determining what sort of cost savings are likely to be forthcoming. From my personal experience with customers, it often turns out that little to no cost savings actually result.
b) improve agility – This one is more clear cut. When on-premise systems are purchased and your requirements change, often you may find out that you under or overbought and that adjusting capacity, starting up or shutting down systems or simply running power, planning for cooling, running network and storage cables, to name just a few tasks can take weeks or months. Cloud data centers often pre-provision technology to be ready for growth and changes in demands plus this is the business they are in, so they tend to be very good at keeping ahead of the demands for their services. Admittedly, some customers are also excellent at this and those that have chosen IBM Power Systems with PowerVM find that making adjustments to systems is so easy that agility is not a major issue. I know of some customers that purchase larger systems than initially required with large amounts of Capacity on Demand CPUs and memory so that growth can be accommodated without any need for physical changes, simply logical activations to deal with this very issue.
c) elasticity and scaling – Elasticity is usually considered in a cost context, i.e. pay for what you use, which cloud models do very well with utility models and use of shared infrastructure plus ability to charge per unit regardless of what size systems are required, meaning nothing is lost if you start on one size system and have to move to another. Scaling usually refers to the ability to add almost an unlimited number of additional servers very quickly and easily, once against because cloud providers focus on this and are very good at rapid provisioning. Is this required for S/4HANA is a more important question. After going through a proper sizing, just about all customers get something wrong. A study by Solitaire Interglobal [iii] a few years ago revealed that customer using x86 systems for SAP, on average, were quoted a starting price that was no more than 40% of the eventual cost. I have seen this personally with undersized offerings or ones that “answered the mail” but did not address necessary project requirements. Customers that have experienced this sort of cost overrun will find a cloud option especially attractive because of the ability to seamlessly move between systems or scale-out as necessary. By comparison, that same Solitaire study showed that customers that purchased IBM Power Systems for SAP were quoted a starting price of 85% to 90% of the eventual cost. Once again, that is because we ask the right questions up front so sizes of systems are much more accurate, most project requirements have been accounted for and overruns are less common. These sorts of customers may not find cloud quite as much of a boon for scaling. On the elasticity front, Power Systems offer a pay as you go model with capacity on demand or flexible financing, so this issue can also be addressed for on-premise implementations.
d) CapEx vs. OpEx – Cloud is all OpEx. Some customers’ CFOs have decided that this is necessary even though the rationale is not always clear to those of us without a finance or business degree. Leases for on-premise systems can be structured to be mostly or all OpEx. Of course, that only accounts for the systems, so data center infrastructure would likely fall more under CapEx. If those are sunk assets, however, then unless they are to be sold, depreciation under CapEx will continue whether SAP systems are moved to the cloud or not.
I am sure there are plenty of other reasons to move to the cloud. I would simply encourage customers to get informed about the challenges of migration; the costs once real corporate requirements are included; the security and control or lack thereof you will have of your mission critical systems; the options you can utilize to resolve some of the issues driving you to cloud today. For any customer that would like to have a discussion with me about these issues, costs and solutions, please respond to this blog or send me an email: afreude@us.ibm.com
